
근묵자흑
Kubernetes Pattern: Singleton Service 본문
왜 싱글톤 서비스가 필요한가?
쿠버네티스는 본질적으로 수평적 확장과 고가용성을 위한 다중 레플리카를 권장합니다. 하지만 현실의 많은 애플리케이션은 정확히 하나의 활성 인스턴스만을 요구합니다. 데이터베이스 마이그레이션 작업, 스케줄링된 태스크, 메시지 큐 컨슈머, 동시성을 처리할 수 없는 레거시 시스템 등이 대표적인 예입니다. 이번 장에서는 쿠버네티스 환경에서 싱글톤 서비스를 구현하는 검증된 패턴들에 대해 알아보겠습니다.
쿠버네티스에서 싱글톤 패턴의 도전 과제
철학적 충돌: 고가용성 vs 일관성
쿠버네티스의 설계 철학과 싱글톤 요구사항 사이의 근본적인 긴장이 독특한 도전과제를 만들어냅니다. 쿠버네티스는 애플리케이션이 수평적으로 확장 가능하고 중복성을 통해 인스턴스 장애를 견딜 수 있다고 가정합니다. 싱글톤 서비스는 정의상 이러한 가정을 위반합니다.
이러한 불일치는 리더 선출, 리소스 경합, 가용성 보장과 관련된 복잡한 시나리오로 이어집니다. 예를 들어, 네트워크 파티션이 발생했을 때 ReplicaSet은 "최소한 하나"의 인스턴스를 보장하려 하지만, 이는 일시적으로 두 개의 인스턴스가 실행되는 상황을 만들 수 있습니다.
구현 방식
- StatefulSet -- 엄격한 싱글톤
StatefulSet with replicas: 1은 안정적인 네트워크 아이덴티티와 순서가 있는 배포 시맨틱을 통해 가장 엄격한 싱글톤 보장을 제공합니다.
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: singleton-stateful
namespace: singleton-test
spec:
serviceName: "singleton-service"
replicas: 1
selector:
matchLabels:
app: singleton-app
template:
metadata:
labels:
app: singleton-app
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "9090"
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: ["singleton-app"]
topologyKey: "kubernetes.io/hostname"
terminationGracePeriodSeconds: 30
containers:
- name: singleton-app
image: myapp:1.0
ports:
- containerPort: 8080
name: http
- containerPort: 9090
name: metrics
volumeMounts:
- name: data
mountPath: /data
livenessProbe:
httpGet:
path: /health
port: http
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /ready
port: http
initialDelaySeconds: 5
periodSeconds: 5
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: ["ReadWriteOnce"]
storageClassName: "fast-ssd"
resources:
requests:
storage: 10GiStatefulSet의 주요 장점:
- 예측 가능한 Pod 이름 (
singleton-stateful-0) - 네트워크 파티션 시에도 At-Most-One 시맨틱 보장
- 영구 스토리지와의 안정적인 연결
- 순서가 있는 시작과 종료
StatefulSet 싱글톤 검증
# 테스트 1: 싱글톤 배포 및 데이터 영속성
kubectl apply -f statefulset-singleton.yml
kubectl wait --for=condition=ready pod -l app=singleton-app -n singleton-test --timeout=60s
# Pod 상태 확인
kubectl get pods -n singleton-test -l app=singleton-app
# 결과: singleton-stateful-0 단일 Pod만 실행
# 데이터 영속성 테스트
kubectl exec -n singleton-test singleton-stateful-0 -- cat /data/counter.txt
# 초기값: 44
# Pod 강제 재시작
kubectl delete pod singleton-stateful-0 -n singleton-test --force --grace-period=0
# 재시작 후 데이터 확인
kubectl exec -n singleton-test singleton-stateful-0 -- cat /data/counter.txt
# 결과: 65 (데이터 유지됨)테스트 결과 분석:
- 정확히 하나의 인스턴스만 실행
- Pod 재시작 후에도 데이터 영속성 유지
- PVC를 통한 상태 보존 확인
- Deployment -- 상태가 없는 싱글톤
짧은 싱글톤 위반을 견딜 수 있는 상태가 없는 애플리케이션의 경우:
apiVersion: apps/v1
kind: Deployment
metadata:
name: singleton-deployment
namespace: singleton-test
spec:
replicas: 1
strategy:
type: Recreate # 업데이트 중 다중 인스턴스 방지
selector:
matchLabels:
app: singleton-app
template:
metadata:
labels:
app: singleton-app
spec:
containers:
- name: singleton-app
image: myapp:1.0
ports:
- containerPort: 8080
resources:
requests:
cpu: "500m"
memory: "1Gi"
limits:
memory: "2Gi" # CPU 제한 없음 - 버스트 용량 허용
env:
- name: POD_NAME
valueFrom:
fieldRef:
fieldPath: metadata.nameRollingUpdate 대신 Recreate 전략을 사용하여 업데이트 중 일시적인 다중 인스턴스를 방지합니다.
Recreate 전략 검증
# Deployment 배포
kubectl apply -f deployment-singleton.yml
# 이미지 업데이트로 Recreate 전략 테스트
kubectl set image deployment/singleton-deployment -n singleton-test singleton-app=busybox:1.35
# Pod 상태 모니터링
kubectl get pods -n singleton-test -l app=singleton-deployment --watch
# 결과: 기존 Pod 종료 → 새 Pod 생성 (동시 실행 없음)CronJob -- 주기적인 싱글톤 작업
배치 작업이나 주기적인 싱글톤 작업에는 CronJob이 자연스러운 싱글톤 동작을 제공합니다:
apiVersion: batch/v1
kind: CronJob
metadata:
name: singleton-batch-job
namespace: singleton-test
spec:
schedule: "0 2 * * *" # 매일 오전 2시
concurrencyPolicy: Forbid # 동시 실행 방지
successfulJobsHistoryLimit: 3
failedJobsHistoryLimit: 1
startingDeadlineSeconds: 300
jobTemplate:
spec:
parallelism: 1
completions: 1
backoffLimit: 2
activeDeadlineSeconds: 3600 # 1시간 제한
template:
spec:
restartPolicy: OnFailure
containers:
- name: batch-processor
image: batch-processor:1.0
command: ["python", "process_daily_reports.py"]CronJob 동시성 정책
# CronJob 배포
kubectl apply -f cronjob-singleton.yml
# 실행 상태 확인
kubectl get cronjob -n singleton-test
# NAME SCHEDULE SUSPEND ACTIVE
# singleton-cronjob */5 * * * * False 0
# singleton-cronjob-replace */3 * * * * False 1
# Job 실행 로그 확인
kubectl logs -n singleton-test -l app=singleton-batch --tail=10concurrencyPolicy 테스트 결과:
Forbid: 이전 작업 실행 중이면 새 작업 건너뜀Replace: 이전 작업 취소하고 새로 시작
쿠버네티스 리더 선출
리더 선출의 기본 개념
리더 선출(Leader Election)은 분산 시스템에서 여러 인스턴스 중 하나만 특정 작업을 수행하도록 보장하는 핵심 패턴입니다. 쿠버네티스 환경에서 리더 선출이 필요한 이유는 다음과 같습니다:
왜 리더 선출이 필요한가?
- 중복 작업 방지: 여러 컨트롤러가 동일한 리소스를 동시에 수정하는 것을 방지
- 순서 보장: 작업의 일관된 순서를 보장
- 고가용성: 리더 실패 시 자동으로 새 리더 선출
- 확장성: 여러 인스턴스를 배포하면서도 싱글톤 동작 보장
리더 선출 알고리즘의 핵심 요소
# 리더 선출의 3가지 핵심 타이밍
LeaseDuration: 15s # 리더가 리더십을 유지하는 기간
RenewDeadline: 10s # 리더가 리스를 갱신해야 하는 데드라인
RetryPeriod: 2s # 리더가 아닌 노드가 리더십을 확인하는 주기타이밍 관계 공식:
RenewDeadline < LeaseDuration
RetryPeriod < RenewDeadline이 관계를 위반하면 스플릿 브레인이나 리더 부재 상황이 발생할 수 있습니다.
Kubernetes의 리더 선출 메커니즘
쿠버네티스는 세 가지 리소스 타입을 리더 선출에 사용할 수 있습니다:
1. Lease (권장)
apiVersion: coordination.k8s.io/v1
kind: Lease
metadata:
name: my-leader-election
namespace: default
spec:
holderIdentity: "pod-abc-123" # 현재 리더
leaseDurationSeconds: 15
acquireTime: "2025-09-27T10:00:00Z"
renewTime: "2025-09-27T10:00:10Z"장점:
- 가장 가벼운 리소스
- coordination API의 일부로 설계됨
- 불필요한 필드 없음
2. ConfigMap (레거시)
apiVersion: v1
kind: ConfigMap
metadata:
name: my-leader-election
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"pod-abc-123",...}'단점:
- 더 많은 스토리지 사용
- 본래 용도와 다른 사용
3. Endpoints (레거시)
apiVersion: v1
kind: Endpoints
metadata:
name: my-leader-election
annotations:
control-plane.alpha.kubernetes.io/leader: '{"holderIdentity":"pod-abc-123",...}'리더 선출 동작 흐름
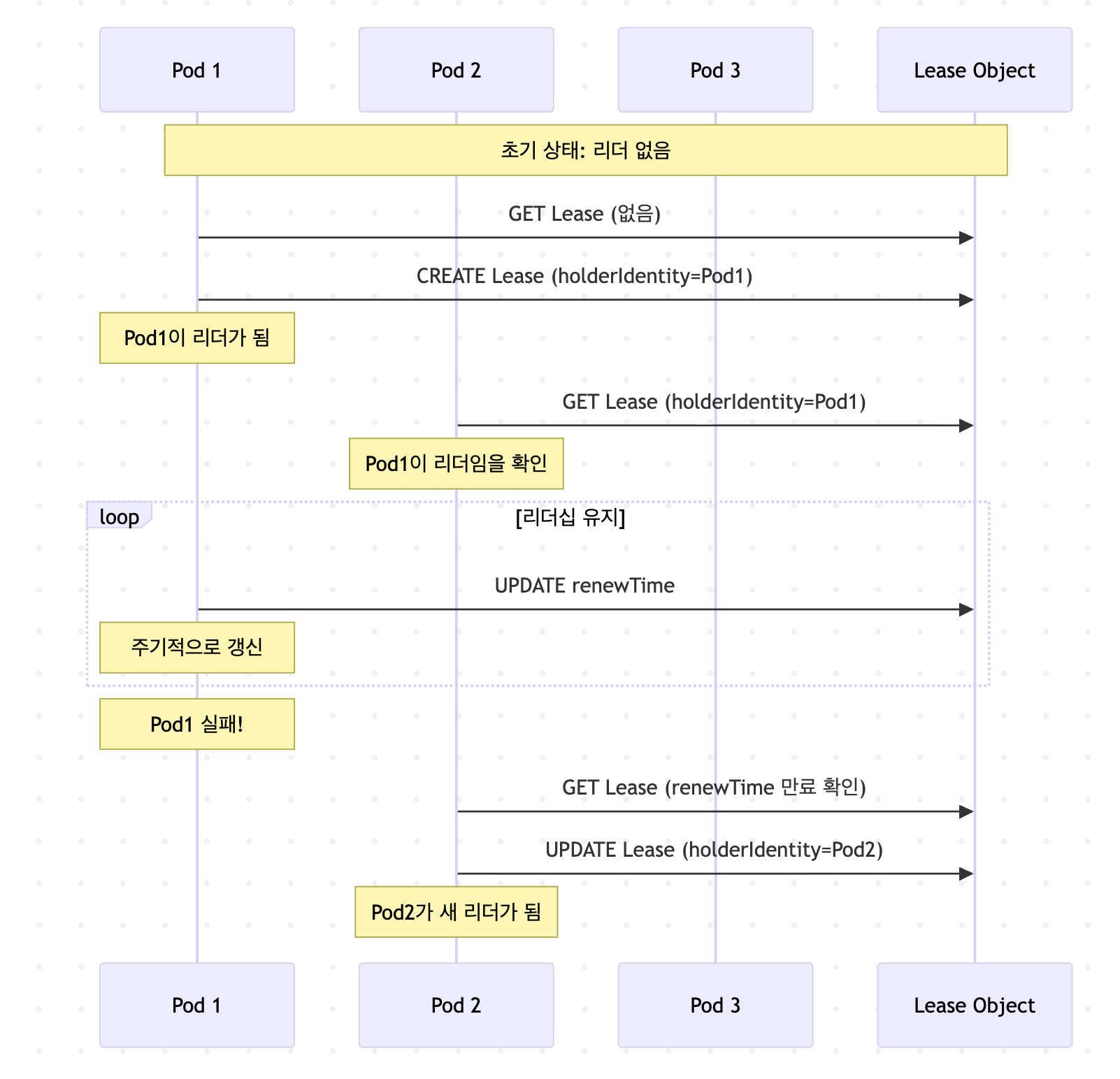
리더 선출의 고급 패턴
1. 다중 리더 선출 (Sharded Leadership)
특정 작업을 여러 리더가 분담하는 패턴:
// 샤드별 리더 선출
func getShardedLockName(shardID int) string {
return fmt.Sprintf("leader-election-shard-%d", shardID)
}
// 각 샤드마다 독립적인 리더
for i := 0; i < numShards; i++ {
go runLeaderElection(getShardedLockName(i), i)
}2. 우선순위 기반 리더 선출
apiVersion: apps/v1
kind: Deployment
metadata:
name: priority-leader
spec:
template:
spec:
priorityClassName: high-priority # 높은 우선순위
containers:
- name: leader
env:
- name: LEADER_ELECTION_PRIORITY
value: "100" # 커스텀 우선순위 값3. 리더 선출 with Graceful Handover
func (s *SingletonApp) gracefulHandover(ctx context.Context) error {
// 1. 새 리더 후보에게 신호 전송
s.signalHandoverReady()
// 2. 진행 중인 작업 완료
s.finishOngoingWork()
// 3. 상태 체크포인트 저장
s.saveCheckpoint()
// 4. 자발적으로 리더십 포기
return s.releaseLeadership()
}일반적인 리더 선출 문제와 해결책
문제 1: Thundering Herd
문제의 본질
Thundering Herd는 분산 시스템의 고전적인 문제입니다. 리더가 갑자기 실패하면, 모든 대기 중인 팔로워들이 "리더가 없다!"는 것을 거의 동시에 감지합니다. 예를 들어 100개의 Pod가 있고 각 Pod가 2초마다 리더 상태를 확인한다면, 리더 실패 후 2초 내에 100개의 Pod가 모두 Lease 업데이트를 시도합니다. 이는 etcd에 초당 50개의 write 요청을 발생시켜 성능 한계를 넘을 수 있습니다.
해결 전략: Exponential Backoff + Jitter
Exponential Backoff는 실패할 때마다 대기 시간을 2배씩 늘리는 전략입니다. Jitter는 각 Pod마다 무작위 추가 대기 시간을 더해 요청을 분산시킵니다.
func calculateBackoffWithJitter(attempt int) time.Duration {
// 핵심 로직: 지수적 증가 + 무작위성
baseDelay := 2 * time.Second
maxDelay := 60 * time.Second
// 2^attempt * baseDelay 계산
delay := baseDelay * (1 << uint(attempt))
if delay > maxDelay {
delay = maxDelay
}
// 0~delay 사이의 무작위 값 추가
jitter := time.Duration(rand.Int63n(int64(delay)))
return delay + jitter
}실제 효과:
- 100개 Pod가 2-5초 사이의 각기 다른 시점에 요청
- API 서버 부하가 시간적으로 분산됨
- etcd write 스파이크 방지
문제 2: 네트워크 파티션과 스플릿 브레인
스플릿 브레인 발생 시나리오
네트워크 파티션 시 가장 위험한 시나리오를 단계별로 분석하면:
- 정상 상태: Pod A가 마스터 노드에서 리더 역할 수행
- 네트워크 단절: 마스터와 워커 노드 간 통신 두절
- 이중 리더: Pod A는 여전히 자신이 리더라고 믿고, Pod B가 새 리더로 선출
- 데이터 불일치: 두 리더가 동시에 상충되는 작업 수행
Fencing Token을 통한 근본적 해결
Fencing Token은 "진짜 리더"를 구별하는 단조 증가하는 숫자입니다:
type FencedOperation struct {
fenceToken int64
operation func()
}
func (f *FencedOperation) ExecuteWithFencing(currentToken int64) error {
// 더 높은 토큰만 작업 허용
if currentToken <= f.fenceToken {
return fmt.Errorf("stale fence token: %d <= %d",
currentToken, f.fenceToken)
}
f.fenceToken = currentToken
f.operation()
return nil
}
// 외부 시스템에서의 검증
// SQL: UPDATE data SET value = ? WHERE fence_token < ?작동 원리:
- 각 리더 선출마다 증가하는 토큰 발급
- 모든 외부 시스템이 토큰 검증
- 네트워크 분리된 이전 리더의 작업 자동 차단
문제 3: 리더 정체 (Zombie Leader)
좀비 리더의 위험성
좀비 리더는 기술적으로는 살아있지만 실제 업무는 수행하지 못하는 상태입니다:
- CPU 스로틀링: 리더가 CPU 제한에 걸려 작업 불가, 하지만 리스 갱신은 계속
- 데드락: 메인 스레드는 데드락, 리스 갱신 스레드는 정상
- 외부 의존성 장애: DB 연결은 끊겼지만 K8s API와는 통신 가능
방어 전략
// 자동 리더십 포기
func (h *HealthyLeader) MonitorHealth(ctx context.Context) {
ticker := time.NewTicker(5 * time.Second)
for {
select {
case <-ticker.C:
if !h.IsHealthy() {
log.Println("건강하지 않음, 리더십 포기")
h.releaseLeadership()
return
}
case <-ctx.Done():
return
}
}
}PDB 동작 검증
# PDB 적용
kubectl apply -f pdb.yml
# PDB 상태 확인
kubectl get pdb -n singleton-test
# NAME MIN AVAILABLE ALLOWED DISRUPTIONS
# singleton-stateful-pdb 1 0
# 노드 드레인 시뮬레이션 (minikube 단일 노드 제약)
# 실제 환경에서는 다음과 같이 동작:
# kubectl drain <node-name> --ignore-daemonsets --delete-emptydir-data
# 결과: PDB로 인해 차단됨Pod Disruption Budget 전략
PDB의 근본적인 딜레마
Pod Disruption Budget은 쿠버네티스가 자발적 중단(voluntary disruption)을 수행할 때 최소한 유지해야 할 Pod 수를 지정합니다. 싱글톤 서비스에서 이는 심각한 모순을 만듭니다.
싱글톤 PDB 패러독스
싱글톤 서비스의 경우:
- replicas = 1 (싱글톤이므로)
- minAvailable = 1 (서비스 가용성 필요)
- 결과: allowedDisruptions = 0
이는 다음을 의미합니다:
- ❌ 노드 유지보수 불가능
- ❌ 클러스터 업그레이드 차단
- ❌ 노드 드레인 실패
unhealthyPodEvictionPolicy 해결책 (K8s 1.26+)
정책 옵션별 동작 분석
1. IfHealthyBudget (기본값)
spec:
minAvailable: 1
unhealthyPodEvictionPolicy: IfHealthyBudget # 기본값- 건강한 Pod 수가 PDB를 만족하면 비정상 Pod 퇴거
- 싱글톤에는 여전히 문제 (건강한 Pod가 1개뿐)
2. AlwaysAllow (싱글톤 최적)
spec:
minAvailable: 1
unhealthyPodEvictionPolicy: AlwaysAllow- 비정상 Pod는 PDB 계산에서 완전 제외
- Pod가 NotReady 상태면 즉시 교체 가능
- 싱글톤 서비스에 이상적
Kubernetes Coordinated Leader Election (1.31+ Alpha)
개념과 필요성
Coordinated Leader Election은 Kubernetes 1.31에서 도입된 알파 기능으로, control plane 컴포넌트들의 업그레이드 과정에서 발생하는 리더 전환을 더 부드럽게 만들기 위해 설계되었습니다.
기존 리더 선출의 문제점:
- 구 버전 리더가 강제 종료됨
- 모든 리더십이 한 번에 이전됨
- 새 리더가 모든 컨트롤러를 동시에 시작
- 일시적인 API 서버 부하 급증
Coordinated Leader Election :
리더십을 컨트롤러별로 점진적으로 이전:
- T+0: Deployment 컨트롤러 리더십 양도
- T+5: ReplicaSet 컨트롤러 리더십 양도
- T+10: Service 컨트롤러 리더십 양도
# LeaderMigrationConfiguration
apiVersion: controlplane.config.k8s.io/v1alpha1
kind: LeaderMigrationConfiguration
leaderName: "migration-controller"
resourceLock: "leases"
controllerLeaders:
- name: "deployment-controller"
component: "kube-controller-manager"
version: "1.30"
- name: "deployment-controller"
component: "kube-controller-manager"
version: "1.31"
쿠버네티스에서 싱글톤 서비스를 구현하는 것은 여러 요소를 신중하게 고려해야 하는 복잡한 작업입니다.
이러한 패턴들과 테스트 결과를 통해 아래와 같은 사항들을 확인할 수 있습니다.
- StatefulSet이 가장 엄격한 싱글톤 보장을 제공
- Deployment + Recreate는 상태가 없는 싱글톤에 적합
- CronJob은 배치 작업을 위한 자연스러운 선택
- 리더 선출은 고가용성과 싱글톤의 균형점
- PDB는 신중한 설정이 필요
'k8s > kubernetes-pattern' 카테고리의 다른 글
| Kubernetes Pattern: Stateless Service (8) | 2025.10.18 |
|---|---|
| Kubernetes Pattern: Stateful Service (0) | 2025.10.11 |
| Kubernetest Pattern: DaemonService (4) | 2025.09.20 |
| Kubernetes Pattern: Periodic Job (2) | 2025.09.13 |
| Kubernetes Pattern: Batch Job (3) | 2025.09.06 |